 |
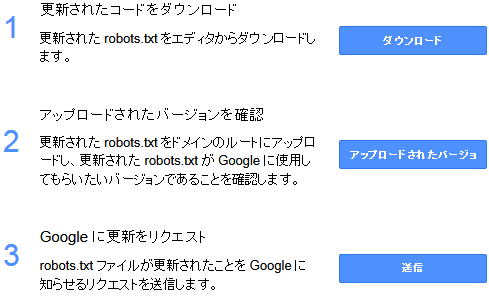
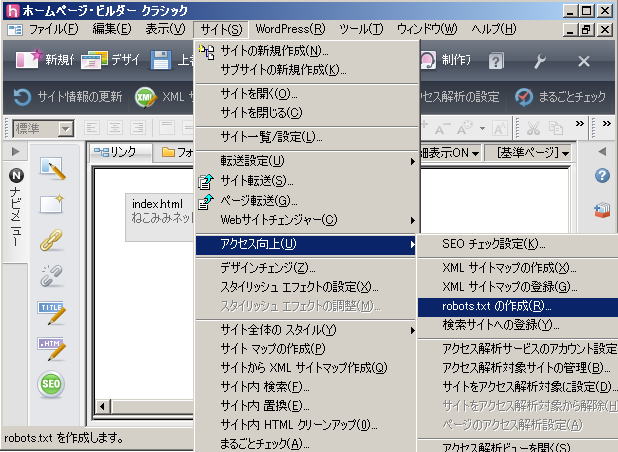
ホームページビルダー上端のメニューから、「サイト」 → 「アクセス向上」 → 「robots.txt の作成」をクリックします | |
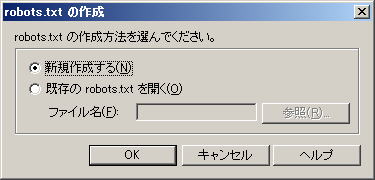 |
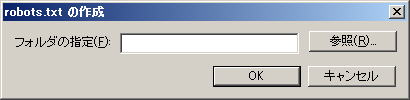
初めて作成する場合は、「新規作成する」にチェックが付いた状態のまま、「OK」をクリックします | |
 |
「参照」をクリックします | |
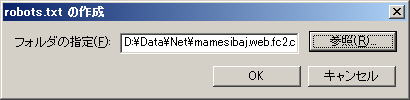 |
パソコン上のサイトを作成しているフォルダーを指定して、「OK」をクリックします | |
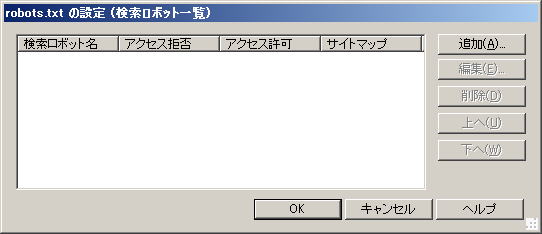 |
「追加」をクリックします | |
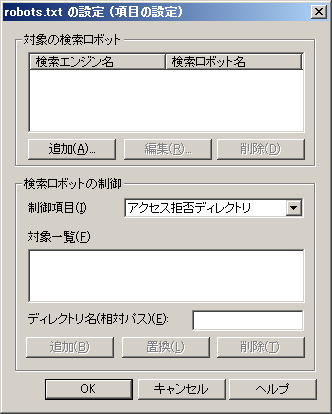 |
「追加」をクリックします | |
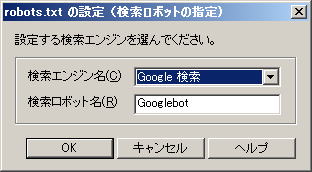 |
「検索エンジン」も右側にある「▼」をクリックします | |
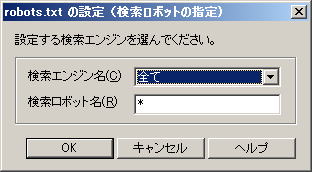 |
「検索エンジン」で「全て」を選択して、「OK」をクリックします | |
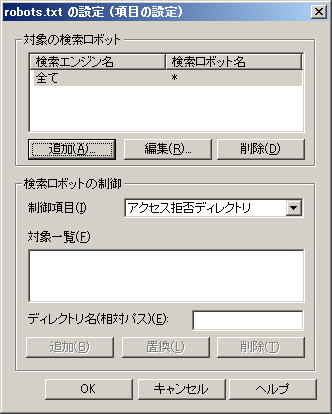 |
「検索エンジン」で「全て」が選択された状態です 「検索ロボットの制御」の「制御項目」は、デフォルトで、「アクセス拒否ディレクトリ」になっていますので、必要に応じて変更します |
|
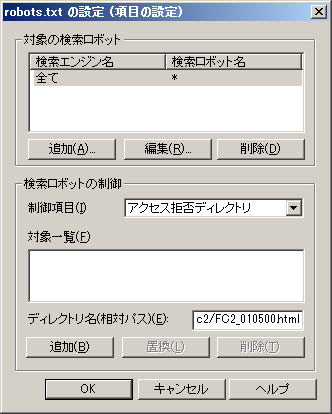 |
下の方にある「ディレクトリ名(相対パス)」に、クローラーアクセスを制御したいフォルダー(ディレクトリ)、または、ファイル(ページ)名を相対パス(URL)指定で入力し、「追加」をクリックします | |
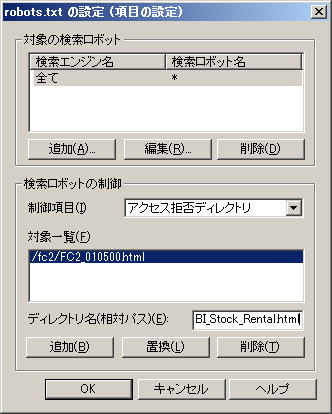 |
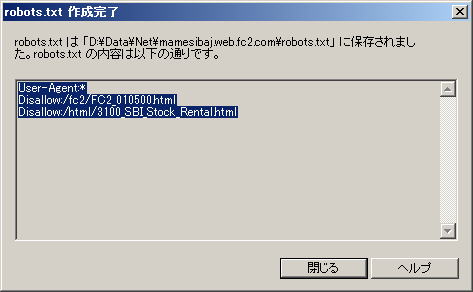
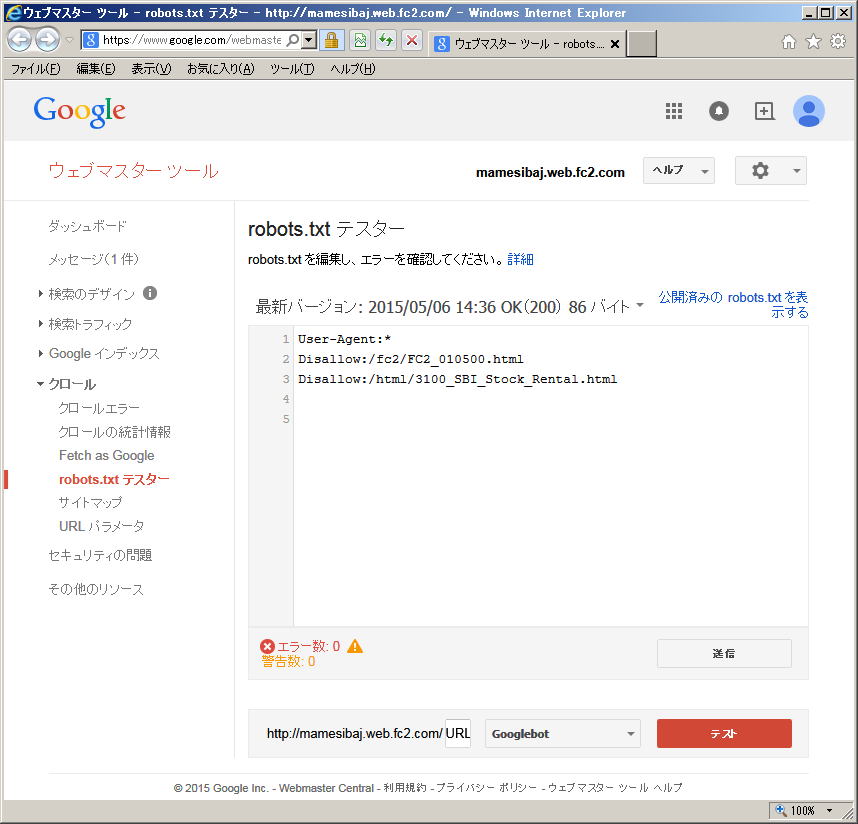
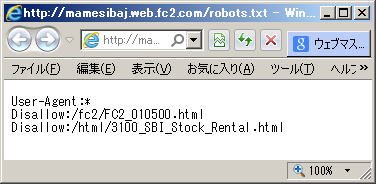
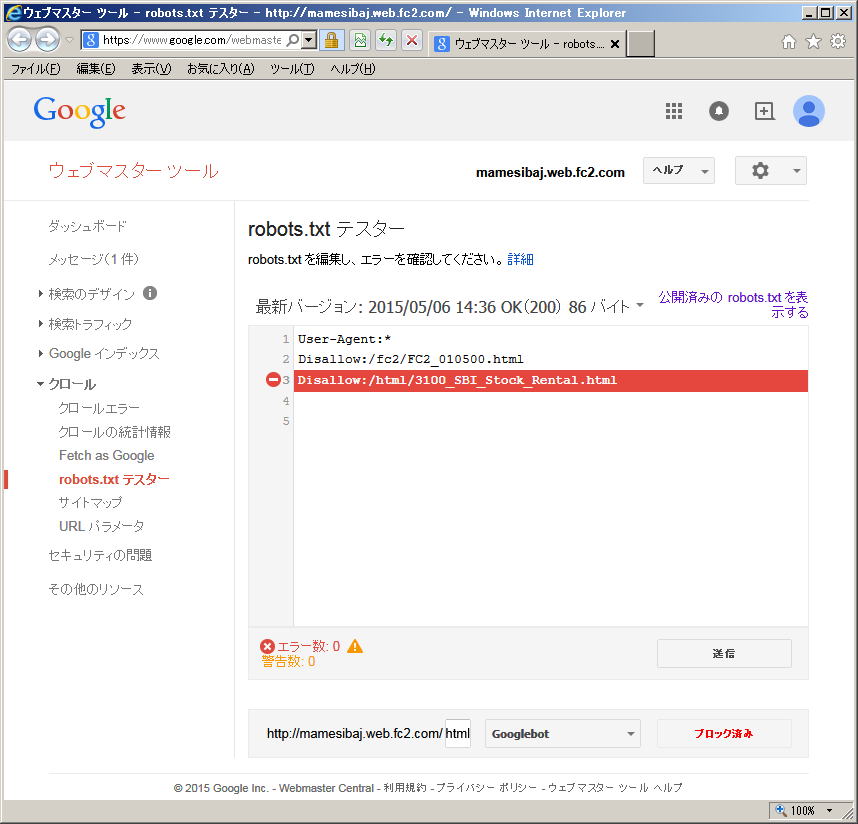
この例では、ルートディレクトリ直下の「fc2」フォルダーに入っている「FC2_010500.html」ファイル(ページ)へのクロールアクセスを拒否しています | |
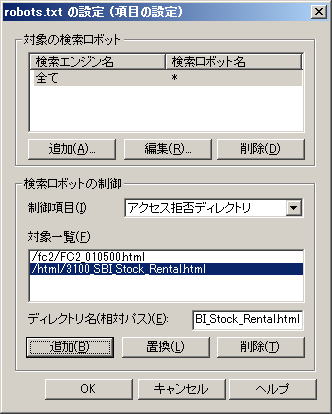 |
制御したい項目が複数ある場合、続けて、「ディレクトリ名(相対パス)」に入力し、「追加」をクリックします この例では、ルートディレクトリ直下の「html」フォルダーに入っている「3100_SBI_Stock_Rental.htm」ファイル(ページ)へのクロールアクセス拒否を追加しています 全て入力し終えたら「OK」をクリックします |
|
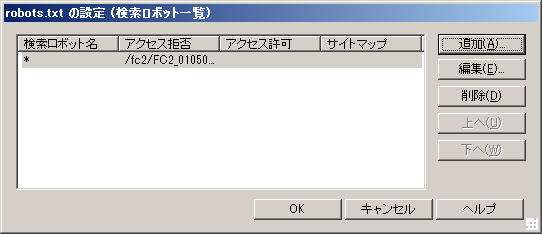 |
「OK」をクリックします |